MEMORIA TÉCNICA
Registro de la Propiedad Intelectual de la Comunidad de Madrid
Obra: WHeat-Jobs | Fenotipo
versión 1.0
1. Identificación de la obra y declaración de autoría
La presente memoria técnica describe la estructura, arquitectura, organización funcional, persistencia, lógica algorítmica y subsistemas principales de la obra software WHeat-Jobs | Fenotipo, a efectos de identificación técnica de la obra y de exposición ordenada de sus elementos originales de diseño e implementación.
Se hace constar que el Dr. Ricardo Manuel Trigo Calonge es autor del diseño funcional, de la arquitectura de software, de la organización lógica del sistema, del modelo algorítmico, del diseño de persistencia y del código fuente incorporado a la presente obra. La eventual utilización de herramientas de asistencia a la programación no altera la autoría sobre la concepción, selección, validación e integración final del resultado.
2. Ficha técnica y entorno de ejecución
| Naturaleza de la obra: | Aplicación web de gestión biométrica, clínica y evaluación funcional heurística |
| Arquitectura de software: | Patrón Modelo-Vista-Controlador (MVC) con separación entre presentación, servicios, persistencia técnica, cálculo y evaluación heurística |
| Lenguaje y framework: | C# v13.0 | .NET 10.0 | ASP.NET Core MVC | Visual Studio 2026 |
| Gestión de datos: | SQL Server y Entity Framework Core (Code-First) |
| Autenticación y acceso: | Microsoft AspNetCore Identity con tipado fuerte de modelos y validación estructurada |
| Motores de cálculo: | Motor hardcodeado, motor declarativo y modo comparativo dual con resolución en tiempo de ejecución |
| Unidad lógica de entrada: | HealthDashDataBundle como Colección de Datos Funcionales de perfil, biometría diaria y analítica clínica |
| Entorno de despliegue: | Servidor web con soporte .NET Runtime y almacenamiento interno de ficheros funcionales de trabajo |
| Canal de importación masiva: | Subida web de ficheros comprimidos mediante ZIP fragmentado por bloques (chunked upload), con recomposición secuencial en servidor, extracción controlada y persistencia interna del export.xml |
| Importación analítica clínica: | Lectura automática de informes de laboratorio en PDF mediante IA nativa (AnthropicClient con documento base64 directo, sin OCR previo): extracción de hasta 60 biomarcadores con conversión automática de unidades por laboratorio, revisión interactiva con semáforo de rangos de referencia y persistencia en AnaliticaClinica |
Esquema de la arquitectura lógica del sistema WHeat-Jobs | Fenotipo
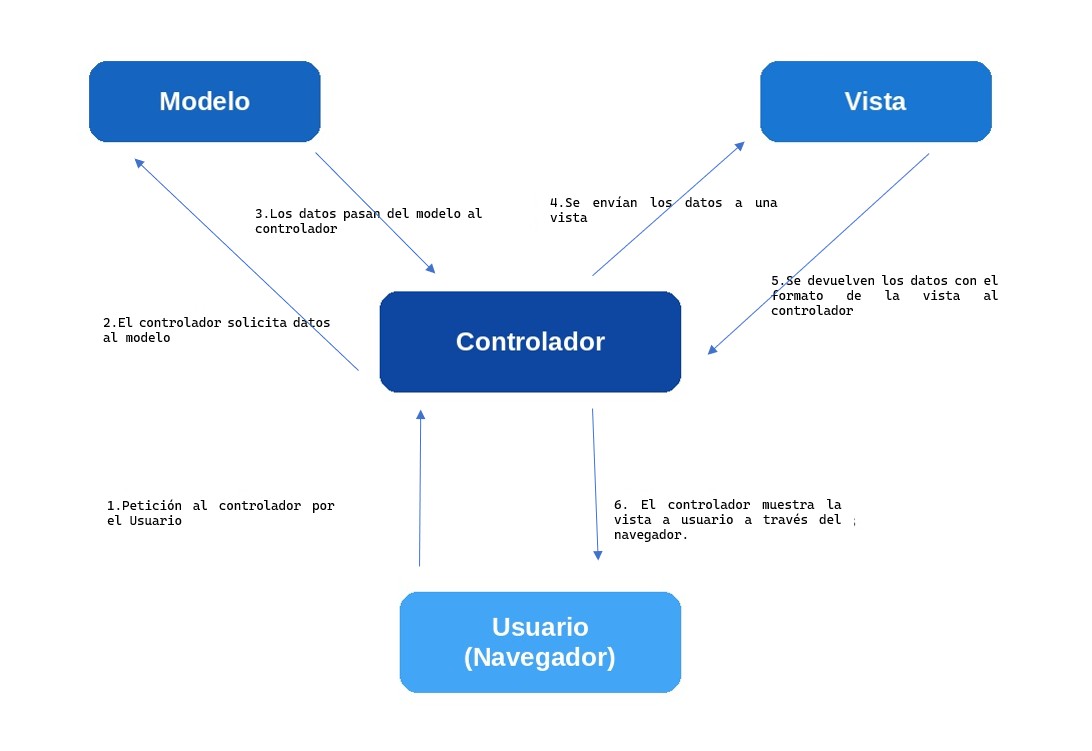
Diagrama 1
3. Descripción funcional y algorítmica
3.1. Descripción funcional general
WHeat-Jobs | Fenotipo es una plataforma web orientada a la integración, estructuración y explotación funcional de datos biométricos diarios, analíticas clínicas y variables personales de contexto, con la finalidad de generar indicadores compuestos, seguir su evolución temporal y asistir en la interpretación funcional del estado del usuario.
El sistema integra tres fuentes de datos primarias:
PerfilPersonal,
BiodataDiaria y
AnaliticaClinica.
A partir de ellas construye una unidad lógica de entrada denominada
Colección de Datos Funcionales o HealthDashDataBundle,
que constituye la base inmediata del cálculo técnico.
La aplicación no se limita al almacenamiento o visualización de información, sino que incorpora una arquitectura propia de formación de contexto fisiológico, cálculo técnico, persistencia histórica, reconstrucción temporal y evaluación heurística orientada a objetivo.
Junto a la gestión manual y estructurada de datos fisiológicos y clínicos, el sistema incorpora un
subsistema de importación masiva destinado a la ingestión de exportaciones externas
de datos de salud generadas por plataformas de terceros y dispositivos personales. En su estado actual,
dicho subsistema admite la subida de ficheros comprimidos ZIP que contienen un
export.xml de gran tamaño, evitando la carga directa monolítica del XML mediante una estrategia de
subida fragmentada por bloques, recomposición en servidor, extracción controlada y persistencia interna.
Esta arquitectura desacopla la fase de transporte del fichero desde el equipo del usuario y la fase de lectura funcional del XML ya persistido. En consecuencia, el sistema no opera sobre rutas locales del cliente, sino sobre una copia interna validada y almacenada en servidor, reutilizable para lecturas posteriores, generación de archivos reducidos por semana y trazabilidad técnica.
La formación de la Colección de Datos Funcionales sigue reglas temporales determinadas. La analítica clínica utilizada es la última analítica disponible con fecha igual o anterior a la fecha de cálculo. La biometría diaria, por su parte, se selecciona dentro de una ventana temporal configurable de días naturales, aplicada de forma homogénea al cálculo actual y al cálculo histórico reconstruido.
En la configuración operativa vigente, la ventana biométrica queda expresada, con carácter general, como VentanaBiométrica = [ FechaCalculo − 6 días , FechaCalculo ], siendo ambas fechas inclusivas. En consecuencia, el número máximo teórico de registros biométricos integrados por cálculo es de 7 registros diarios, salvo ausencia material de datos en alguna de las fechas comprendidas.
El núcleo funcional actual se articula mediante tres índices:
Score SNC,
Score Metabólico y
Score Bioenergético.
Dichos scores se obtienen a partir del HealthDashDataBundle, incorporando reglas de interpretación,
umbrales fisiológicos y, cuando procede, un factor corrector de fiabilidad analítica en función de la antigüedad
de la analítica utilizada.
Junto a dichos scores compuestos, la aplicación incorpora además una línea de análisis paralela
centrada en la evolución temporal de variables directas de BiodataDiaria
y un subsistema específico de análisis energético-metabólico diario basado en
EnergyDailyBalance.
Estas capas no sustituyen al scoring, sino que lo complementan al permitir examinar tendencias recientes,
balance energético, suficiencia proteica y disponibilidad energética funcional desde una perspectiva diaria
y longitudinal.
El cálculo técnico se articula mediante una fachada de motor de score capaz de resolver dinámicamente distintas implementaciones. El sistema soporta un motor hardcodeado de referencia operativa, un motor declarativo alineado funcional y matemáticamente con el motor hardcodeado, y un modo de comparación dual destinado al contraste técnico entre ambos.
A diferencia de una implementación declarativa meramente efímera o dependiente únicamente del estado dinámico del sistema, la arquitectura actual incorpora persistencia histórica específica del motor declarativo. En cada ejecución declarativa se registra no solo el resultado numérico obtenido, sino también el estado declarativo efectivo aplicado en ese momento, incluyendo serialización estructurada, metadatos de versión y huella criptográfica de integridad.
La persistencia del estado declarativo efectivo permite reconstruir con precisión el modelo utilizado en cualquier cálculo histórico, facilitando auditoría técnica, comparación longitudinal entre configuraciones y verificación de consistencia lógica entre versiones.
3.2. Fundamentación científico-técnica del motor hardcoded
El motor hardcoded de WHeat-Jobs | Fenotipo no se configura como un sistema de diagnóstico médico autónomo, sino como un modelo funcional de estratificación fisiológica. Su estructura combina, de una parte, umbrales apoyados en referencias clínicas o biomédicas consolidadas y, de otra, tramos heurísticos internos orientados a monitorización funcional, detección de desviaciones y generación prudencial de recomendaciones.
En el dominio metabólico, la base científica es comparativamente más estable. La glucosa basal y la hemoglobina glicosilada (HbA1c) se apoyan en estándares contemporáneos de clasificación de normoglucemia, prediabetes y diabetes, que el sistema reutiliza en forma simplificada para producir scoring funcional. De igual modo, triglicéridos y colesterol HDL se incorporan como variables de contexto cardiometabólico.
La variable pasos / NEAT no constituye un criterio diagnóstico clínico formal, pero sí un marcador funcional razonable del volumen de movimiento habitual. La evidencia y las recomendaciones internacionales de actividad física respaldan la relevancia del movimiento cotidiano y del descenso del sedentarismo como ejes de salud general.
En el dominio SNC, el modelo utiliza HRV, sueño, frecuencia cardiaca en reposo, tensión arterial y magnesio sérico. La literatura apoya que la HRV disminuye con la edad y que una mayor variabilidad suele asociarse a mejor flexibilidad autonómica y mejor capacidad de recuperación; no obstante, los puntos de corte concretos empleados por el motor no equivalen a umbrales diagnósticos universales.
En materia de sueño, el motor combina el tiempo total de sueño con el sueño profundo y, cuando existe dato disponible, con otras variables de arquitectura del sueño. Las guías de referencia recomiendan entre 7 y 9 horas en adultos de 18 a 64 años, y entre 7 y 8 horas en mayores de 65. A partir de esa edad la relación entre duración del sueño y resultados en salud muestra una curva en U: tanto el déficit como el exceso se asocian a mayor mortalidad, y la arquitectura del sueño cambia fisiológicamente con la edad (menor proporción de sueño profundo, mayor fragmentación). Los umbrales del motor reflejan estas matizaciones, sin pretender equivalencia con criterios diagnósticos.
La frecuencia cardiaca en reposo se incorpora porque una frecuencia más elevada se ha asociado, a nivel poblacional, con mayor mortalidad total y cardiovascular. En cuanto a la presión arterial, el sistema utiliza una traducción prudente de la literatura y de las guías contemporáneas.
El bloque de magnesio sérico posee respaldo biomédico, aunque con menor uniformidad absoluta en torno al concepto de nivel óptimo. La literatura reciente sobre estandarización de rangos de referencia propone prestar especial atención a niveles séricos en torno a 0,85 mmol/L.
En el dominio bioenergético, hemoglobina, TSH y ferritina constituyen el núcleo base. La hemoglobina se emplea como marcador indirecto de capacidad de transporte de oxígeno; la TSH, como proxy de regulación tiroidea; y la ferritina, como indicador de reservas de hierro.
La modulación bioenergética por sueño profundo, HRV y frecuencia cardiaca en reposo responde a una hipótesis fisiológica plausible: el estado de recuperación autonómica y del sueño condiciona la expresión funcional del sistema bioenergético.
3.3. Evaluación heurística orientada a objetivo
HealthDashDataBundle constituye la Colección de Datos Funcionales de entrada;
los resultados numéricos de cada motor constituyen los scores técnicos;
y el snapshot funcional representa la síntesis resultante de la consideración conjunta
de los motores, su comparación técnica, la interpretación heurística,
las recomendaciones y el prediagnóstico funcional.
Sobre el resultado técnico de cálculo, el sistema aplica una segunda capa de evaluación heurística destinada a determinar la dirección del estado, la magnitud del cambio, la alineación con el objetivo y el comportamiento de la pauta.
Esta lógica permite emitir decisiones operativas sobre la pauta, distinguiendo entre mantenimiento, ajuste, intensificación o sustitución, sin confundir la mera convergencia con el cumplimiento efectivo del objetivo.
El sistema dispone de persistencia técnica del cálculo y de
persistencia heurística del resultado operativo actual. La primera se registra en
HealthScoreHistory; la segunda, en HealthEvolutionSnapshot.
El cálculo histórico puede visualizarse como score técnico persistido o como reconstrucción histórica recalculada sobre datos fuente, manteniéndose el score técnico persistido como referencia principal de trazabilidad.
3.4. Especificación práctica del algoritmo
Especificación práctica del algoritmo
El algoritmo opera en ciclos de captura de contexto, importación, agregación, cálculo, evaluación heurística y persistencia.
export.zip, subida web fragmentada por bloques,
recomposición secuencial del ZIP en servidor, extracción controlada del export.xml
y persistencia interna del XML resultante como fuente estable de lectura.
export.xml ya persistido, el sistema genera un XML reducido por semana natural,
reconstruye por fecha la información fisiológica relevante mediante lectura estructural en streaming
y transforma el resultado en registros normalizados compatibles con BiodataDiaria.
PerfilPersonal, selección de la ventana temporal configurada de
BiodataDiaria y determinación de la AnaliticaClinica
más próxima anterior o igual a la fecha de cálculo.
BiodataDiaria.
HealthScoreHistory,
del resultado heurístico actual en HealthEvolutionSnapshot
y del balance energético diario en EnergyDailyBalance.
En suma, el sistema analiza el estado actual del usuario, la dirección de su evolución y el comportamiento de la pauta, a fin de determinar si la intervención aplicada aproxima efectiva y progresivamente al objetivo funcional previsto.
3.5. Arquitectura de variables del algoritmo
Arquitectura de variables del algoritmo
El sistema distingue entre variables de latencia aguda y crónica. Aunque la base de datos admite un conjunto amplio de parámetros biométricos, clínicos y de perfil, el motor heurístico opera en su estado actual sobre un núcleo progresivamente auditado de variables esenciales, susceptible de ampliación o recalibración.
TemperaturaCorporal: registro térmico basal.HRV: equilibrio del sistema nervioso autónomo.FrecuenciaCardiacaReposo: pulso basal y recuperación.SueñoProfundoMinutos: reparación física.SueñoRemMinutos: recuperación neurocognitiva.Peso: masa corporal total.PasosDiarios: movimiento NEAT.LitrosAgua: hidratación registrada.CaloriasConsumidas: ingesta energética diaria.
GlucosaAyunas: azúcar basal.HemoglobinaGlicosilada: media glucémica de largo plazo.Trigliceridos: grasas circulantes.ColesterolHDL: fracción protectora.ColesterolLDL: fracción aterogénica.ProteinaCReactiva: inflamación de bajo grado.Ferritina: almacén de hierro.TSH: regulación tiroidea.VitaminaD3: soporte inmunometabólico.GGT / ALT: marcadores hepáticos.Creatinina / FiltradoGlomerular: eficiencia renal.CPK: daño muscular.MagnesioSerico: regulador neuromuscular y metabólico.
4. Arquitectura de datos y lógica de negocio
El sistema se apoya en una arquitectura relacional y de servicios orientada a separar con claridad los datos fuente, la formación de la Colección de Datos Funcionales de entrada, el cálculo técnico, la interpretación heurística y la persistencia del resultado.
Datos base: PerfilPersonal
Define el marco basal y estratégico del usuario. Dispone de CRUD completo.
- Biometría basal: edad, sexo, altura y composición.
- Contexto: profesión, clima, entorno y hábitos.
- Dirección: objetivo principal del usuario.
Datos base: BiodataDiaria
Registra la evolución cotidiana del usuario. Dispone de CRUD completo.
- Actividad: ejercicio, pasos, carga diaria.
- Recuperación: HRV, sueño, fatiga, estrés.
- Homeostasis: pulso, temperatura, SpO2, hidratación.
Datos base: AnaliticaClinica
Aporta validación bioquímica estructural. Dispone de CRUD completo.
- Metabolismo: glucosa, HbA1c, lípidos.
- Inflamación y reservas: ferritina, PCR, vitaminas.
- Función orgánica: renal, hepática, endocrina.
Servicios funcionales principales
- HealthDashDataService: construcción de la Colección de Datos Funcionales a partir de perfil, biometría diaria y analítica clínica.
- HealthImportController: orquestación MVC del proceso de importación, lectura semanal, generación de XML reducido y agregación posterior.
- HealthImportPathService: resolución centralizada de rutas internas para
export.xml, XML reducidos semanales y directorios temporales. - HealthScoreService: fachada central del cálculo técnico de scores.
- HardcodedHealthScoreEngine: implementación operativa estable de referencia.
- DeclarativeHealthScoreEngine: implementación basada en configuración dinámica de bloques, inputs y reglas.
- HealthScoreModeResolver: resolución del motor activo en tiempo de ejecución.
- HealthRecommendationService: recomendación inmediata basada en estado actual.
- HealthScoreHistoryService: persistencia del score técnico del cálculo.
- DeclarativeHistoryService: persistencia histórica específica del motor declarativo.
- HealthScoreBackfillService: reconstrucción retrospectiva del histórico técnico.
- BioDataEvolutionService / BioDataTrendAnalysisService: análisis de tendencias sobre variables persistidas en
BiodataDiaria. - EnergyDailyBalanceService: cálculo y persistencia del balance energético diario, macronutrientes, proteína/kg, alcohol, gasto total y clasificación oficial del estado energético.
- EnergyDailyBalanceQueryService: construcción de modelos de consulta y visualización del análisis metabólico diario.
- EnergyExpenditureModelService: aplicación del modelo de ajuste de gasto basal y activo importado.
- HealthTrendService: análisis y proyección de tendencia sobre histórico persistido.
- HealthEvolutionService: evaluación evolutiva orientada a objetivo.
- HealthEvolutionOrchestrator: coordinación del flujo heurístico completo.
- PlanAdjustmentService: decisión sobre mantenimiento, ajuste, intensificación o sustitución de la pauta.
- AnaliticaInterpretService: interpretación clínica asistida por IA de una
AnaliticaClinicaya persistida, generando un informe HTML contextualizado. - AnaliticaPdfImportService: extracción automática de biomarcadores desde PDF de laboratorio mediante
AnthropicClientcon documento nativo base64; aplica reglas de conversión de escala (×10ⁿ, mg/dL↔mmol/L, pmol/L↔ng/dL) y retorna el resultado para revisión antes de persistir. - OllamaCompletionService / ClaudeCompletionService: motores de completado IA para Ollama Cloud y Claude API respectivamente.
- AiBackgroundWorker: servicio hospedado de procesamiento asíncrono de tareas IA mediante cola de canal interno (
Channel<T>). - IBackgroundTaskQueue / IAiResultStore / IAiTimingService: infraestructura de encadenamiento, almacenamiento de resultados y estimación de tiempos de respuesta IA.
- AiProviderSettings: gestión en tiempo de ejecución del proveedor IA activo (global y por administrador), con consola de administración dedicada.
- HistoriaPacienteService: generación del informe de revisión histórica parcial para el período seleccionado: compila perfil, evolución de scores SNC/MET/BIOE, balance energético por período, macronutrientes medios, analítica clínica con verificación de ~55 parámetros contra rangos de referencia (
BuildParametros) y apéndice de registros diarios brutos; construye las variables de contexto para el prompt IA (HistoriaPacientePromptVars). - HistoriaPacientePromptSeeder: seeder que persiste en base de datos la plantilla versionada
HISTORIA_PACIENTEcon sus bloques de contenido (IaPromptBlock), incluyendo las reglas de interpretación clínica estáticas y los marcadores[FUERA DE RANGO]para guiar al modelo.
4.1. Subsistema de análisis de tendencias de BiodataDiaria
Junto al cálculo técnico de scores y a la evaluación heurística global, el sistema incorpora un
subsistema específico de análisis de tendencias sobre la entidad BiodataDiaria,
destinado a observar la dirección, estabilidad y magnitud del cambio de variables fisiológicas cotidianas.
Este subsistema opera sobre una ventana temporal seleccionable de registros diarios y permite obtener una lectura sintética de la evolución reciente de variables como peso, cintura, frecuencia cardiaca en reposo, HRV, sueño, distancia recorrida, pasos y energía activa.
Desde el punto de vista arquitectónico, este módulo constituye una capa analítica intermedia entre la persistencia diaria de biometría y la evaluación heurística global.
4.2. Subsistema de análisis metabólico diario y dinámica energética funcional
El sistema incorpora un subsistema específico de análisis energético-metabólico diario, destinado a interpretar la relación entre ingesta, gasto energético, distribución nutricional, proteína relativa al peso corporal, actividad física y balance energético final.
La fuente técnica principal de este subsistema es la entidad EnergyDailyBalance,
generada a partir de BiodataDiaria y recalculada mediante servicios internos.
Dicha entidad consolida la energía ingerida, el gasto basal ajustado, el gasto activo ajustado,
el gasto total, el balance energético, los macronutrientes, el alcohol ingerido,
la proteína por kilogramo de peso corporal y el estado energético resultante.
La clasificación oficial del estado energético se centraliza en
EnergyDailyBalanceService.ResolveEnergyStatus, evitando que las vistas,
prompts o módulos auxiliares reclasifiquen el balance mediante umbrales paralelos.
- DeficitSevero: balance ≤ -900 kcal.
- DeficitModerado: balance ≤ -450 kcal.
- DeficitLigero: balance ≤ -150 kcal.
- Equilibrado: balance < 150 kcal.
- SuperavitModerado: balance ≤ 500 kcal.
- SuperavitAlto: balance > 500 kcal.
Sobre esta base se articula el módulo de Análisis metabólico diario, que ofrece una lectura funcional del día evaluado: ingesta total, gasto estimado, balance calórico, distribución de hidratos, proteínas, grasas y alcohol, suficiencia proteica relativa y compatibilidad del patrón observado con preservación de masa magra o pérdida progresiva de grasa.
De forma complementaria, el módulo de Dinámica metabólica representa visualmente la evolución funcional del día mediante una curva por fases, integrando balance energético acumulado e índice relativo de disponibilidad energética. Este índice no constituye una magnitud física directa, sino una señal sintética orientativa que combina balance energético, proteína/kg, hidratos, grasas y alcohol.
Desde el punto de vista arquitectónico, ambos módulos forman una capa analítica específica
dentro del sistema, conectada con BiodataDiaria y EnergyDailyBalance,
pero separada del motor principal de scores.
Formación de la Colección de Datos Funcionales y regla temporal de cálculo
La unidad efectiva de cálculo del sistema es el HealthDashDataBundle, integrado por:
PerfilPersonal, una colección acotada de BiodataDiaria y una
AnaliticaClinica seleccionada por proximidad temporal anterior o igual a la fecha de cálculo.
La selección de biometría diaria se realiza mediante una ventana temporal natural de N días, siendo N un parámetro configurable del sistema. Cuando N = 7, equivale a [ FechaCalculo − 6 , FechaCalculo ].
La regla temporal aplicada queda reflejada en histórico a través de los campos
FechaBioInicio, FechaBioFin, NumeroRegistrosBioUsados y
ReglaAplicada.
Arquitectura de importación masiva y persistencia interna del XML
El sistema incorpora una arquitectura específica para la ingestión de exportaciones XML de gran tamaño, basada en la subida de un fichero ZIP fragmentado en bloques.
Una vez reconstruido el ZIP, el sistema realiza una extracción controlada del contenido,
localiza el export.xml válido y lo copia a la ubicación interna definitiva del usuario.
Subsistema de importación estructurada y generación automática de BiodataDiaria
La arquitectura actual incorpora un subsistema específico de ingestión documental,
reducción estructural, agregación funcional y transformación normalizada de datos externos
en registros persistentes de BiodataDiaria.
Una vez persistido el export.xml, la aplicación genera archivos reducidos por semana natural,
construidos mediante lectura secuencial en streaming y filtrado selectivo de nodos relevantes.
Sobre dichos XML reducidos semanales actúa un motor de agregación diaria diseñado para reconstruir, por fecha, la información fisiológica relevante contenida en el documento.
Esta cadena captura documental → persistencia interna → reducción semanal → agregación diaria → normalización → persistencia en BiodataDiaria constituye un componente técnico propio del sistema.
Validación y tipado: los modelos emplean DataAnnotations, precisión decimal
y restricciones de persistencia mediante Entity Framework Core y SQL Server.
4.3. Calibración del factor de corrección de ingesta calórica (OllamaIntakeCorrectionFactor)
La IA estima la ingesta calórica a partir de los alimentos declarados por el usuario. Sin embargo,
dicha estimación presenta una desviación sistemática que varía según el individuo, sus hábitos y la precisión
de la declaración. El sistema incorpora un mecanismo de calibración empírica que calcula un factor
multiplicador (OllamaIntakeCorrectionFactor) para corregir esa desviación.
Principio físico del balance energético
La calibración se fundamenta en la identidad del balance energético:
Donde ΔPeso es la variación de peso corporal en el período analizado (negativo si hubo pérdida, positivo si hubo ganancia) y 7700 kcal/kg es el equivalente energético aproximado de un kilogramo de tejido adiposo. Esta igualdad permite deducir cuántas kilocalorías reales ingirió el usuario a partir de su gasto medido y la evolución de su peso, sin depender en absoluto de la estimación de la IA.
El factor de corrección se obtiene entonces como:
Si el factor resultante es mayor que 1, la IA subestima la ingesta real; si es menor que 1, la sobreestima. Aplicar este factor a las estimaciones futuras de la IA produce una ingesta corregida más cercana a la realidad fisiológica del usuario.
Dos variantes del factor: Endpoint y Regresión OLS
El servicio EnergyCalibrationRegressionService calcula dos estimaciones independientes del ΔPeso:
- ΔPeso Endpoint: diferencia simple entre el último peso registrado en el período y el primero. Es directo pero sensible a fluctuaciones puntuales (retención de líquidos, hora del pesaje, etc.).
- ΔPeso Regresión (OLS): se ajusta una recta de mínimos cuadrados ordinarios sobre toda la serie de pesos del período. La pendiente de esa recta (kg/día) multiplicada por el número de días proporciona un ΔPeso suavizado, menos afectado por el ruido diario y más representativo de la tendencia real del tejido corporal.
A cada variante de ΔPeso le corresponde un factor independiente (FactorEndpoint y
FactorRegresion).
Factor recomendado y criterio de ponderación
El factor final que se propone al usuario (FactorRecomendado) pondera las dos variantes en
función del coeficiente de determinación R² de la regresión del peso:
Si R² < 0,30 → FactorRecomendado = FactorEndpoint
Un R² bajo indica alta variabilidad en el peso (ruido fisiológico, mediciones irregulares), por lo que la regresión no es fiable y se usa únicamente el endpoint. Con R² suficiente, la regresión recibe mayor peso (70%) por ser más robusta frente al ruido de corto plazo.
El factor resultante se limita al rango [0,80 – 2,50] como salvaguarda ante datos atípicos o períodos de registro incompleto.
Evaluación de la calidad de los datos
El servicio clasifica automáticamente la fiabilidad de la calibración en cuatro niveles:
| Nivel | Criterio |
|---|---|
| Excelente | ≥ 60 días con ingesta y R² ≥ 0,50 |
| Buena | ≥ 30 días con ingesta y R² ≥ 0,30 |
| Aceptable | ≥ 20 días con ingesta |
| Insuficiente | < 15 días con ingesta o sin datos de peso |
Con menos de 15 días de ingesta declarada el sistema devuelve calidad «Insuficiente» y no aplica el factor. Se recomienda un mínimo de 30 días para un factor fiable.
4.4. Automatización de Ingesta (IntakeAutomationService)
Módulo de siembra sintética que genera una semana completa de registros de ingesta plausibles a partir del historial fisiológico del usuario, sin intervención de IA generativa. El algoritmo es puramente estadístico:
Algoritmo de generación
- Se requieren al menos 30 días previos con ingesta registrada en el período de referencia. Sin ese mínimo el servicio rechaza la operación.
-
Para cada macro (
ProteinasIngeridasGr,HidratosIngeridosGr,GrasasIngeridasGr,AlcoholIngeridoGr) se calculan la media (μ) y la desviación típica (σ) por día de semana (lunes…domingo) sobre el período de referencia elegido. Si un día de semana no tiene historial, se usa la estadística global del período. -
La σ efectiva se limita:
σ_ef = min(σ_hist, μ × 0,25). Así la variación máxima garantizada es el ±25 % de la media, evitando valores absurdos cuando el historial es ruidoso. -
Cada valor se muestrea como
μ + N(0,1) × σ_ef(método Box-Muller) y se recorta al intervalo[0, μ + 2,5·σ_ef]. -
Las calorías se calculan por coherencia a posteriori:
Kcal = Prot×4 + HC×4 + Grasa×9 + Alcohol×7. No se reescalan los macros — la coherencia calórica es informativa, no forzada. -
Solo se siembran los días que no tienen ya ingesta en
BiodataDiaria. Los días con datos previos se muestran como "ya existe" en la previsualización y no se modifican.
Limitación y advertencia de uso
La automatización introduce inexactitud estadística en los registros de ingesta. Los valores generados son plausibles con el patrón histórico del usuario pero no son reales. Afectan al balance energético, a la calibración del modelo y a los informes evolutivos. Se recomienda utilizar esta función únicamente cuando no hay datos reales disponibles y la brecha en el historial impide el funcionamiento de otros módulos. Es mejor que no tener nada, pero nunca equivale a la declaración real de ingesta.
4.5. Asistente IA conversacional (AiAssistantController)
Panel de chat contextual accesible desde cualquier página de la aplicación mediante un botón flotante. No requiere tablas propias ni migraciones: el historial de conversación se mantiene íntegramente en el cliente (array JS) y se serializa en texto dentro del user prompt en cada petición.
Arquitectura y contexto
-
Reutiliza la interfaz
IAiCompletionServiceexistente, compatible con Claude API y Ollama Cloud, sin ningún cambio en los motores subyacentes. -
El system prompt se construye dinámicamente en cada petición con: (a) manual de funcionalidades
de Fenotipo, (b) perfil personal del usuario (
PerfilesPersonales) y (c) los últimos 30 días deBiodataDiariaen formato tabular compacto, incluyendo pasos, sueño, FC, HRV, SpO₂, peso, energía basal, energía activa, gasto total, ingesta calórica, balance y macros (P/HC/G). - El historial se limita a 10 turnos (20 entradas) para controlar el consumo de tokens.
-
Las respuestas se renderizan con marked.js. El contenedor del chat lleva
class="tex2jax_ignore"para que MathJax (cargado globalmente) no procese los símbolos matemáticos de las respuestas del modelo. -
El endpoint
POST /AiAssistant/Chatestá protegido con[Authorize]y token anti-CSRF.
4.6. Módulo de detección y medición de adaptación metabólica
La adaptación metabólica (adaptive thermogenesis) designa la reducción del gasto energético real por encima de la explicable por cambios de masa corporal, como respuesta homeostática del organismo a la restricción calórica prolongada. El sistema incorpora un módulo propio que cuantifica este fenómeno de forma automática y longitudinal.
Principio de cálculo
El módulo compara dos estimaciones del TDEE (Gasto Energético Total Diario) para el período analizado:
-
TDEE teórico: media del campo
EnergyDailyBalance.EnergiaGastoTotalKcal, calculado por el modelo energético (EnergyExpenditureModelService) a partir de Mifflin-St Jeor, actividad y NEAT declarado. -
TDEE real estimado: derivado por conservación de energía:
TDEE_real = (ΣIngestaCorregida − ΔPeso_kg × 7 700) / n_díasdonde ΣIngestaCorregida aplica el factor
OllamaIntakeCorrectionFactorsolo sobre macros (el alcohol usa fórmula determinista, sin corrección).
La variación de peso se obtiene mediante regresión OLS sobre la serie histórica de peso si R² ≥ 0,25 (criterio de señal suficiente); en caso contrario se usa la diferencia entre endpoints, reduciendo el sesgo de retención hídrica.
Adaptación = TDEE_teórico − TDEE_real. Un valor positivo indica que el cuerpo gasta menos calorías de las que el modelo predice: es la medida operativa de la adaptación.
Niveles de adaptación y alertas
| Nivel | Umbral | Implicación clínica |
|---|---|---|
| SinAdaptacion | < 100 kcal | Gasto coherente con el modelo teórico. |
| Leve | 100–250 kcal | Ajuste inicial; vigilar proteína y NEAT. |
| Moderada | 250–500 kcal | Considerar reactivación metabólica. |
| Severa | > 500 kcal | Adaptación significativa; reevaluar pauta. |
Alertas automáticas: reactivación metabólica cuando Adaptación > 250 kcal y período ≥ 20 días; proteína insuficiente cuando cobertura proteica media < 80 % del objetivo.
Serie histórica y persistencia
El módulo calcula una serie histórica de 12 ventanas de 28 días, desplazadas 7 días entre sí,
que permite visualizar la evolución de la adaptación a lo largo de los últimos meses.
Los snapshots se persisten bajo demanda del usuario en MetabolicAdaptationSnapshots
y se representan visualmente con Chart.js (barras de adaptación y línea TDEE teórico vs real).
Causas documentadas en el modal de información del módulo: regulación hormonal (leptina, T3, cortisol, ghrelina), supresión del SNA, colapso del NEAT, aumento de eficiencia muscular (Rosenbaum: 20-25 % a −10 % de peso) y rol de la proteína (TEF, preservación de masa magra, efecto NEAT). Evidencia de reactivación metabólica prolongada: estudio MATADOR (Byrne 2017 — reducción de adaptación del 50 % con descansos de 2 semanas).
5. Persistencia funcional del sistema
HealthScoreHistory
Snapshot técnico persistido del cálculo funcional.
- FechaCalculo: fecha efectiva del cálculo.
- FechaAnaliticaUsada: analítica clínica tomada como referencia temporal.
- FechaBioInicio / FechaBioFin: ventana real de biometría diaria utilizada.
- NumeroRegistrosBioUsados: número real de registros diarios incluidos.
- ScoreSNC / ScoreMetabolico / ScoreBioenergetico: resultado técnico del cálculo.
- ReglaAplicada: regla temporal y técnica declarada para el cálculo.
- EdadEnFechaCalculo: edad computada para la fecha evaluada.
- FactorFiabilidadAnalitica: corrector aplicado por antigüedad de la analítica.
HealthEvolutionSnapshot
Persistencia del resultado heurístico completo de la evaluación operativa vigente.
- Objetivo y dirección.
- Alineación de pauta.
- Score ponderado objetivo.
- Decisión de pauta.
- Justificación y recomendación ajustada.
- Origen de pauta y versión asociada.
UserActivePlan / UserActivePlanVersion
Persistencia real de la pauta activa y de sus versiones.
Permite trazabilidad histórica y vinculación del snapshot heurístico con una versión concreta de pauta.
EnergyDailyBalance
Persistencia diaria del balance energético y nutricional calculado por el sistema.
- Ingesta: energía total ingerida y macronutrientes.
- Gasto: energía basal ajustada, energía activa ajustada y gasto total.
- Balance: diferencia entre ingesta y gasto total.
- Proteína/kg: indicador funcional de suficiencia proteica.
- Alcohol: integración energética y moduladora del día.
- EstadoEnergetico: clasificación oficial centralizada del balance diario.
- ReglaAplicada: versión del modelo de gasto energético utilizado.
HealthScoreMasterParameters y modelo declarativo
Catálogo maestro técnico y estructura declarativa para la configuración progresiva del motor de cálculo.
Comprende parámetros scoreables, bloques, inputs, modelos y futuras reglas o modificadores.
Persistencia interna del import XML
El sistema conserva internamente una copia funcional del export.xml del usuario como fuente estable de lectura.
- Origen: ZIP externo subido por bloques y recombinado en servidor.
- Destino: ruta interna persistente por usuario.
- Función: lectura completa, generación de reducidos semanales y reutilización funcional posterior.
MetabolicAdaptationSnapshot
Snapshot de adaptación metabólica calculada bajo demanda del usuario.
- FechaDesde / FechaHasta: ventana temporal analizada (14–90 días).
- TdeePredichoMediaKcal: media de
EnergyDailyBalance.EnergiaGastoTotalKcal. - TdeeRealEstimadoKcal: TDEE real derivado por balance de masa.
- AdaptacionKcal / AdaptacionPorcentaje: gap TDEE teórico − real.
- Nivel: SinAdaptacion / Leve / Moderada / Severa.
- DeltaPesoKg / R2Peso: cambio de peso y bondad de ajuste OLS.
- CoberturaProteicaMedia: ratio de suficiencia proteica en el período.
HealthScoreDeclarativeHistory
Persistencia técnica específica del motor declarativo.
- Scores persistidos: SNC, Metabólico y Bioenergético.
- Contexto temporal: fecha de cálculo, analítica usada y ventana biométrica aplicada.
- Modelo persistido: serialización JSON completa del estado declarativo efectivo.
- Integridad: hash SHA-256 del modelo declarativo utilizado.
- Trazabilidad: versión del modelo, origen de configuración y existencia de parámetros de usuario.
6. Consola declarativa y parámetros configurables por el usuario
La arquitectura declarativa del sistema incorpora una consola técnica de parametrización destinada a permitir la configuración controlada del motor de cálculo sin necesidad de modificar código fuente.
Los parámetros configurables por el usuario se agrupan en tres categorías: Inputs, Rules y Modifiers.
Resolución de Inputs → Evaluación de Rules → Cálculo de Score Base → Aplicación de Modifiers → Score Final
6.1. Inputs
Un Input representa una variable fisiológica, clínica o derivada que alimenta el motor declarativo.
6.2. Rules
Una Rule transforma el valor de un Input en una puntuación funcional.
6.3. Modifiers
Un Modifier modifica el score ya calculado, mediante ajustes posteriores.
6.4. Efecto matemático y orden de ejecución
Resolver Input → Aplicar Rule → Obtener Score Base → Aplicar Modifier → Emitir Score Final.
7. Instrucciones y logística funcional
Pautas de suministro de datos, uso operativo y explotación funcional del sistema.
01Entrada: Perfil Personal
Datos básicos de marco: biometría basal, contexto personal, hábitos y objetivo funcional.
02Seguimiento diario
Registro manual o importación estructurada de biometría diaria y datos históricos de salud.
03Lectura semanal reducida
Generación de reducidos semanales, agregación diaria y transformación a BiodataDiaria.
04Verificación: Analítica Clínica
Registro analítico para auditoría de recomendaciones, trazabilidad temporal y confirmación bioquímica. Los valores pueden introducirse manualmente o mediante importación automática desde PDF: el informe de laboratorio se envía directamente a la IA, que extrae y convierte hasta 60 biomarcadores; el usuario revisa el resultado con semáforo de rangos y confirma antes de persistir.
8. Elementos diferenciales del sistema
El sistema WHeat-Jobs | Fenotipo no se limita a la recopilación pasiva de variables biométricas o clínicas, sino que integra múltiples capas funcionales destinadas a la interpretación estructurada del estado fisiológico y de su evolución temporal.
8.1. Construcción de la Colección de Datos Funcionales
El sistema genera un objeto funcional unificado, HealthDashDataBundle,
que agrupa perfil personal, biometría diaria y analítica clínica relevante.
8.2. Coexistencia de motores hardcoded y declarativo
La coexistencia de ambos motores permite verificar la equivalencia lógica entre implementaciones y facilita la evolución progresiva del sistema sin pérdida de consistencia histórica.
8.3. Persistencia del contexto completo de cálculo
Cada cálculo se registra junto con su contexto funcional, incluyendo fecha efectiva, intervalo biométrico, analítica clínica, edad fisiológica y regla o motor utilizado.
8.4. Importación estructurada y normalización de datos externos
El sistema transforma exportaciones externas en registros diarios internos normalizados mediante
persistencia del XML, reducción semanal, agregación diaria y transformación a BiodataDiaria.
8.5. Subsistema longitudinal de tendencias sobre BiodataDiaria
Esta capa permite observar la evolución de variables fisiológicas directas y resumir el comportamiento reciente del usuario mediante valores actuales, medias, variaciones y calificación operativa.
8.6. Motor estructural de agregación diaria
El motor admite el tratamiento estructural de nodos simples y compuestos mediante lectura XML en streaming.
8.7. Análisis metabólico diario y dinámica energética funcional
El sistema incorpora una capa específica de análisis energético-metabólico diario, diferenciada del motor general de scores, que permite interpretar el estado funcional del día a partir de ingesta, gasto basal, gasto activo, balance energético, distribución de macronutrientes, alcohol y proteína relativa al peso corporal.
Esta capa se apoya en una fuente determinista centralizada,
EnergyDailyBalance, y utiliza una regla única de clasificación
del estado energético, evitando inconsistencias entre vistas, prompts
e interpretaciones auxiliares.
Junto al análisis metabólico diario, el sistema dispone de una vista de dinámica metabólica que representa visualmente la disponibilidad energética funcional mediante balance acumulado por fases e índice relativo sintético.
8.8. Arquitectura modular y evolución progresiva
La estructura general permite sustituir motores internos, introducir nuevas variables, extender el modelo declarativo y adaptar nuevas fuentes externas sin ruptura funcional.
8.9. Integración de módulos de asistencia inteligente mediante modelos IA
Plataforma activa: Ollama Cloud (proveedor por defecto) / Claude API (alternativo)
Modelo base configurado:
gemma4:31bOrigen de configuración:
OllamaCloud:Model / Claude:ModelGestión de proveedor:
AiProviderSettings con consola de administración dedicada
El sistema incorpora módulos de asistencia funcional basados en modelos de lenguaje ejecutados mediante IA. Estos módulos no sustituyen la lógica determinista del sistema, sino que actúan como capa auxiliar.
En su estado actual, la integración IA se articula en los siguientes módulos: análisis nutricional de ingesta (estimación de macronutrientes y valor energético a partir de alimentos registrados), resumen interpretativo de evolución de BiodataDiaria, análisis integrado de HealthDash (interpretación clínica del estado fisiológico global), interpretación de dinámica metabólica, importación automática de analítica clínica desde PDF (extracción de biomarcadores con conversión de unidades por laboratorio) y revisión histórica parcial con resumen IA (informe longitudinal del período seleccionado con estado funcional, balance energético, nutrición, analítica clínica y recomendaciones priorizadas). Todos ellos operan sobre datos del usuario o sobre resultados previamente calculados por los motores internos del sistema.
La utilización de modelos de lenguaje no altera la autoría sobre la concepción, organización lógica, arquitectura, validación y control final del sistema.
8.10. Arquitectura de procesamiento IA en segundo plano
Las llamadas a modelos de lenguaje, cuyo tiempo de respuesta puede oscilar entre 10 y 90 segundos,
se procesan mediante una arquitectura de cola asíncrona en segundo plano basada en
IHostedService y Channel<T>.
Esta arquitectura desacopla la solicitud del usuario de la espera bloqueante,
permitiendo que la interfaz muestre un indicador de progreso con estimación de tiempo
mientras el resultado se almacena en un ConcurrentDictionary y se recupera
mediante polling desde el cliente. El tiempo estimado se calibra dinámicamente
a partir de mediciones históricas del propio sistema.
8.11. Sistema declarativo de gestión de prompts IA
El sistema incorpora una arquitectura declarativa propia para la gestión, composición y versionado de los prompts utilizados por los módulos de asistencia inteligente. Esta arquitectura permite modificar, extender y versionar el comportamiento de los módulos IA sin necesidad de alterar el código fuente.
La estructura se compone de tres entidades persistidas:
IaPromptTemplate, que define la plantilla activa identificada
por un código funcional y una versión semántica, con system prompt y
user prompt propios;
IaPromptBlock, que representa bloques de contenido reutilizables
y versionados de forma independiente; y
IaPromptTemplateBlock, que establece la composición ordenada de
bloques dentro de cada plantilla mediante SortOrder.
El servicio IaPromptBuilderService actúa como motor de construcción:
localiza la versión activa más reciente de la plantilla identificada por su código,
une los bloques activos en orden, e interpola las variables de contexto mediante
sintaxis {{NombreVariable}}, produciendo el par
SystemPrompt / UserPrompt final que recibe el modelo.
El sistema incluye una consola de administración dedicada que permite gestionar plantillas, bloques y composiciones sin intervención sobre el código fuente, preservando la trazabilidad entre versiones de prompt y resultados producidos.
8.12. Subsistema de importación automática de analíticas clínicas desde PDF
El sistema incorpora un subsistema específico para la ingestión de informes de laboratorio
en formato PDF, orientado a poblar automáticamente la entidad AnaliticaClinica
sin introducción manual de valores.
A diferencia de las arquitecturas habituales basadas en OCR + extracción de texto,
el subsistema envía el PDF directamente como documento nativo en base64 al modelo
claude-haiku a través de AnthropicClient con
DocumentContent / DocumentSource / SourceType.base64,
delegando en el modelo la capacidad de comprensión estructurada del informe.
El sistema aplica un conjunto de reglas críticas de escala en el prompt, necesarias porque los laboratorios expresan magnitudes hematológicas con notación científica variable (×10⁶/µL, ×10³/µL, M/µL, K/µL) y algunos parámetros bioquímicos pueden aparecer en unidades distintas según el laboratorio:
- Hematología: extrae siempre el coeficiente (4,47 de "4,47 × 10⁶/µL"), nunca el valor absoluto.
- PCR: convierte mg/dL → mg/L (×10) si el laboratorio informa en mg/dL.
- Urea: convierte mmol/L → mg/dL (×6,006) si el laboratorio informa en mmol/L.
- Calcio: convierte mmol/L → mg/dL (×4,008).
- Fósforo: convierte mmol/L → mg/dL (×3,097).
- T4 Libre: convierte pmol/L → ng/dL (÷12,87).
La respuesta del modelo se deserializa mediante JsonSerializer con
JsonNumberHandling.AllowReadingFromString a un DTO interno
(AnaliticaJsonDto), que se mapea a AnaliticaClinica
antes de presentarse al usuario.
El flujo de revisión introduce una pantalla intermedia (RevisarImport)
que muestra todos los valores extraídos organizados por categoría clínica
(serie roja / hemostasia, leucocitos, metabolismo / lípidos, enzimas / renal,
micronutrientes / tiroides, orina), con un semáforo de rangos de referencia
(verde ✓ / rojo ⚠️) que permite al usuario detectar visualmente cualquier error
de escala antes de persistir.
La vista incluye un botón de información que documenta, campo a campo, las conversiones de unidad aplicadas y los rangos esperados por laboratorio, garantizando trazabilidad y transparencia del proceso de importación.
8.13. Módulo de revisión histórica parcial con resumen IA
El sistema incorpora un módulo de revisión histórica longitudinal que permite al usuario generar, para cualquier período seleccionado, un informe integrado que consolida todas las dimensiones funcionales disponibles: perfil fenotípico, evolución de scores SNC, Metabólico y Bioenergético, balance energético (ingesta media, gasto basal, gasto activo NEAT, gasto total y balance resultante), macronutrientes medios, analítica clínica con verificación sistemática de rangos de referencia, y apéndice de registros diarios brutos del período.
El módulo HistoriaPacienteService aplica el método BuildParametros()
para comprobar los ~55 parámetros del modelo AnaliticaClinica contra sus rangos de referencia,
marcando cada parámetro con EsAnormal = true cuando el valor cae fuera del rango.
En el informe, los parámetros esenciales y los anormales se destacan visualmente (fondo cálido,
nombre en ámbar, valor en rojo con indicador ⚠); el resto se omite para no sobrecargar la lectura.
El período analizado nunca incluye el día en curso (datos incompletos).
El informe es imprimible directamente como PDF desde el navegador mediante
Layout = null y CSS media print.
El resumen IA se genera de forma asíncrona mediante IBackgroundTaskQueue
(máximo 1 100 tokens) con una plantilla versionada gestionada por HistoriaPacientePromptSeeder.
La plantilla produce cinco párrafos estructurados: estado funcional, balance energético,
nutrición/sueño/composición corporal, analítica clínica (siempre presente aunque todos los valores
sean normales) y recomendaciones priorizadas, con cierre de valoración global.
Los parámetros marcados como [FUERA DE RANGO] en el bloque de datos son señalados
explícitamente por el modelo en el párrafo de analítica y en las recomendaciones.
8.13b. Módulo de evolución longitudinal de parámetros clínico-analíticos
El sistema incorpora un módulo específico de análisis longitudinal de series temporales de analíticas clínicas,
accesible desde el menú Informes / Evolución → Evolución Analítica. Su unidad de procesamiento es la
colección de objetos AnaliticaClinica del usuario filtrada por un intervalo temporal configurable
(presets de 6 meses, 1, 2 y 5 años, o rango de fechas libre).
Visualización por categoría clínica. El módulo genera ocho gráficas Chart.js independientes
(línea continua, sin interpolación forzada, con spanGaps: true para analíticas no consecutivas),
una por sistema fisiológico: perfil lipídico, metabolismo glucémico, función renal, función hepática, tiroides,
inflamación (PCR/VSG), micronutrientes y hematología. Cada serie incluye los valores efectivos de cada
FechaAnalisis como eje X temporal.
Matriz comparativa interactiva. Un modal a pantalla completa presenta todos los biomarcadores
disponibles en una única tabla vertical continua, con las fechas de analítica como columnas y cada parámetro
como fila. Las filas con ningún valor registrado en el período se omiten automáticamente. La última columna
muestra el delta (Δ) entre el primer y el último valor con dato, con codificación semántica de color:
verde cuando la variación es clínicamente favorable para ese parámetro (p.ej. reducción de LDL, incremento
de HDL o filtrado glomerular), rojo cuando empeora, gris cuando es neutro o sin datos suficientes. La
dirección favorable se parametriza individualmente por parámetro mediante el argumento positivo
en la función de renderizado FilaComp().
Interpretación IA longitudinal. El módulo integra un análisis asíncrono de tendencias generado
por el proveedor IA activo (Ollama Cloud o Claude API) mediante la plantilla versionada con código
ANALITICA_EVOLUCION, gestionada por AnaliticaEvolucionPromptSeeder y
editable desde la consola de prompts sin redesplegar. El bloque de datos inyectado como
{{DataBlock}} es una tabla de texto plano estructurada por categorías, con una fila por
parámetro mostrando los valores en cada fecha y el Δ calculado. El servicio
AnaliticaEvolucionAiService encola la tarea en IBackgroundTaskQueue
(tipo ANALITICA_EVOLUCION) y la UI hace polling cada 2 segundos al endpoint
CheckEvolucionIA hasta recibir el HTML interpretativo. El modelo produce exactamente
cinco secciones h6 en HTML parcial, interpretando tendencias sostenidas (≥ 2 registros
consecutivos en la misma dirección), identificando el Δ de los parámetros con variación clínicamente
relevante y agrupando los hallazgos por sistema. La referencia comparativa es siempre el propio
paciente en el tiempo, nunca baremos poblacionales.
La arquitectura reutiliza todos los componentes de infraestructura IA del sistema: el mismo
IAiCompletionService con selección automática de proveedor por rol (admin / usuario),
la misma cola de tareas con timing estimado (IAiTimingService) y el mismo almacén
en memoria IAiResultStore con TTL de 10 minutos. No requiere migración de base de datos;
únicamente la ejecución de la acción de seed /Inicializer/SeedAnaliticaEvolucionPrompt
para registrar la plantilla inicial en IaPromptTemplates.
8.14. Sistema híbrido de estimación nutricional (OFf + IA)
El módulo de ingesta opera en dos modos: IA pura y modo híbrido que consulta la etiqueta real de OpenFoodFacts para productos envasados de marca con fallback a IA para genéricos. Las bebidas alcohólicas se calculan siempre por IA mediante fórmula determinista. Ver sección 11.11 para descripción completa.
8.15. Modelo estadístico de impacto etílico
AlcoholCalibrationService: regresión MCO con F fijo que cuantifica β_alc (retención inmediata),
β_lag (efecto diferido D+1) y β_sleep (índice fisiológico HRV/sueño). Calcula contrafactual de pérdida sin alcohol
y detecta anomalías de eficiencia metabólica. Ver sección 11.12.
8.16. Factor de corrección diferenciado macros/alcohol y alerta de recalibración
El OllamaIntakeCorrectionFactor se aplica solo sobre macros, excluye el alcohol.
El CalibrationAlertService emite aviso automático cuando el balance acumulado supera el umbral individual.
Ver sección 11.13.
8.17. Arquitectura multiusuario y generación de documentación RGPD
Aislamiento completo por UsuarioId en todas las entidades. Generación asistida por IA de consentimientos
informados, políticas de privacidad y contratos profesional-paciente conformes con el RGPD europeo.
Ver secciones 11.14, 11.15 y 11.16.
8.18. Trazabilidad de origen de HRV y comparativa multi-dispositivo (HealthKit vs Oura)
El sistema admite la importación de BiodataDiaria desde dos fuentes de wearable
heterogéneas: la exportación de Apple HealthKit y la API en vivo de Oura
Ring. Ambas alimentan los mismos campos del modelo, pero emplean algoritmos y ventanas
temporales distintos para magnitudes nominalmente equivalentes, lo que exige una capa explícita de
trazabilidad de origen antes de cualquier comparación longitudinal.
El caso más relevante es la variabilidad de la frecuencia cardiaca (HRV): HealthKit
reporta heartRateVariabilitySDNN (algoritmo SDNN), mientras que Oura
reporta average_hrv del periodo de sueño principal (algoritmo RMSSD).
Ambos valores se expresan en milisegundos pero no son numéricamente comparables entre sí. Para
resolverlo, cada registro de BiodataDiaria persiste el enumerado
HrvOrigen (HrvSource: HealthKitSDNN, OuraRMSSD,
Manual, Desconocido), y de forma análoga la frecuencia cardiaca media persiste
FcMediaOrigen (media diaria de HealthKit vs media nocturna de Oura).
El Panel de Recuperación (RecoveryService) explota esta trazabilidad
calculando un baseline independiente por origen
(RecoveryBaseline.Fuente: media, desviación típica y número de muestras sobre una
ventana de 30 días) para la señal de HRV. Cada RecoveryDailyScore conserva el campo
HrvFuente del día evaluado y se compara únicamente contra el baseline de su misma
fuente, evitando contaminar la línea base de un dispositivo con valores de otro.
Como apoyo a la interpretación clínica y técnica de estas disparidades, se incorpora una página de
comparativa multi-dispositivo (HealthKit vs Oura) que documenta, métrica
a métrica de BiodataDiaria, el origen del dato en cada plataforma, su grado de
equivalencia (equivalente directo, aproximación razonable, disparidad que requiere etiquetado o
corrección, o campo exclusivo de una fuente) y el estado de la corrección aplicada. La página
incluye además una nota operativa sobre la configuración de permisos de Oura en HealthKit/Health
Connect, necesaria para evitar que ambas fuentes se mezclen antes de llegar al sistema y se pierda
así la separación de orígenes.
Complementariamente, el módulo Evolución temporal (HealthTimeSeriesController,
IOuraTimeSeriesService) permite visualizar series de mediciones individuales sin
agregación diaria: desde export.xml para los parámetros de HealthKit, o en vivo desde
la API de Oura (/v2/usercollection/heartrate para frecuencia cardiaca intradía y el
subobjeto hrv de /v2/usercollection/sleep para HRV nocturno por RMSSD).
Para SpO₂ y HRV de HealthKit, el sistema calcula además una línea base personal de 3 meses y
compara la media del periodo seleccionado frente a dicha línea base.
8.19. Importación Android — Google Health Connect Takeout
El sistema extiende el subsistema de adquisición de datos con soporte para dispositivos
Android a través del ZIP de Google Takeout (Google Fit / Health Connect).
La arquitectura reutiliza íntegramente la mecánica de subida chunked de iOS
(StartZipUpload → UploadZipChunk) y añade dos acciones propias:
CompleteAndroidZipUpload (previsualización, sin escritura en BD) y
ConfirmAndroidImport (upsert definitivo).
El servicio GoogleHealthConnectImportService detecta automáticamente dos layouts dentro
del mismo ZIP: CSVs de Daily activity metrics (Google Fit, un fichero por día con cabeceras
nominales como Step count, Average heart rate (bpm),
Distance (m)…) y CSVs por tipo de métrica en subcarpetas Health Connect
(detectadas por nombre de fichero: HeartRateVariabilitySdnn,
RestingHeartRate, SleepSession, OxygenSaturation,
RespiratoryRate, BodyTemperature, Weight, Steps).
Ambos formatos pueden coexistir en el mismo ZIP; el acumulador por fecha (BiodataRow)
aplica ??= para que el primer valor encontrado por campo tenga prioridad y los formatos
se complementen sin sobreescribirse.
El flujo de confirmación en dos pasos garantiza que el usuario revise los datos antes de
modificar BiodataDiaria: la previsualización muestra una tabla con filas coloreadas
(verde = registro nuevo, amarillo = actualiza existente) marcadas consultando las fechas ya
presentes en BD para ese UsuarioId. El ZIP ensamblado se mantiene en disco hasta
la confirmación y se elimina inmediatamente después. Un usuario puede combinar importaciones iOS
y Android sobre el mismo período sin conflicto, ya que el upsert por (UsuarioId, Fecha)
es idempotente.
La integración en la vista (Adquisición de datos → Apple / Android (ZIP)) se articula
mediante un selector de plataforma Bootstrap Pills con paneles tab-pane independientes,
compartiendo CSS y estructura de card pero con JS y endpoints separados por plataforma.
8.20. Módulo de adaptación metabólica
El sistema incorpora un módulo específico de detección y cuantificación de adaptación metabólica (adaptive thermogenesis), accesible desde el menú Energía → Adaptación Metabólica. Su función es medir el gap entre el TDEE teórico por el modelo energético propio del sistema y el TDEE real estimado mediante el principio de conservación de energía aplicado sobre la serie histórica de ingesta corregida y variación de masa corporal.
La variación de masa se extrae mediante regresión OLS sobre la serie de peso del período (umbral R² 0,25 para dar prioridad a la estimación de tendencia sobre el endpoint), reduciendo el sesgo asociado a fluctuaciones de retención hídrica y glucógeno. El módulo clasifica la adaptación en cuatro niveles (Sin / Leve / Moderada / Severa), emite alertas de reactivación metabólica y proteína, y permite almacenar snapshots para seguimiento longitudinal.
La vista del módulo ofrece una serie histórica de 12 ventanas de 28 días con gráficas Chart.js y un modal de información exhaustivo que documenta causas hormonales (leptina, T3, cortisol), mecanismos de conservación (NEAT, eficiencia muscular), evidencia científica de reactivación metabólica (estudio MATADOR, Byrne 2017) y limitaciones de la estimación.
9. Notas sobre el método heurístico de ensayo y ajuste progresivo
El término heurístico se emplea para designar un enfoque de decisión apoyado en reglas prácticas, comparación temporal y ajuste progresivo, sin pretensión de sustituir el juicio clínico.
El sistema observa resultados, detecta desviaciones, compara tendencias y reajusta recomendaciones en función del comportamiento real de las variables biométricas y clínicas.
10. Especificación práctica del algoritmo funcional
El funcionamiento operativo del sistema se articula mediante una secuencia ordenada de fases funcionales, cada una de las cuales produce un resultado estructurado que sirve de entrada a la fase siguiente.
FASE 0 — Importación estructurada de datos externos
Recepción, validación estructural y persistencia interna del archivo XML o contenedor comprimido.
FASE 0 BIS — Reducción documental y segmentación semanal
Generación de subconjuntos documentales por semana natural mediante lectura secuencial en streaming.
FASE 1 — Agregación estructural diaria
Reconstrucción diaria de registros, intervalos, entrenamientos, actividad y demás nodos relevantes.
FASE 2 — Normalización y generación de BiodataDiaria
Transformación de agregados diarios en registros normalizados compatibles con BiodataDiaria.
FASE 2 BIS — Cálculo energético diario
A partir de BiodataDiaria, el sistema calcula y persiste el balance energético diario
mediante EnergyDailyBalance, integrando ingesta, gasto basal ajustado,
gasto activo ajustado, gasto total, macronutrientes, alcohol, proteína/kg y estado energético oficial.
Este cálculo constituye la base del análisis metabólico diario y de la dinámica energética funcional.
FASE 3 — Construcción de la Colección de Datos Funcionales
Formación del HealthDashDataBundle con perfil, biometría diaria reciente y analítica válida.
FASE 4 — Ejecución del motor de cálculo
Ejecución del motor hardcoded, declarativo o comparativo sobre la Colección de Datos Funcionales.
FASE 5 — Persistencia del resultado
Registro del resultado junto con su contexto operativo, temporal, técnico y funcional.
11. Elementos de originalidad técnica
La originalidad técnica del sistema WHeat-Jobs | Fenotipo no deriva de la utilización aislada de variables biomédicas conocidas, sino de la estructura funcional que permite integrarlas dentro de un flujo coherente, reproducible y trazable.
11.1. Modelo de Colección de Datos Funcionales
El HealthDashDataBundle consolida variables relevantes para el cálculo en una estructura funcional única.
11.2. Arquitectura dual de cálculo
La coexistencia de motor hardcoded y declarativo permite validación cruzada y evolución controlada.
11.3. Persistencia contextual del cálculo
Cada cálculo se almacena junto con los parámetros, contexto temporal, analítica y motor que lo originaron.
11.4. Pipeline estructurado de importación biométrica
El sistema transforma exportaciones externas en estructuras internas normalizadas mediante lectura secuencial y agregación diaria.
11.5. Integración de lógica heurística funcional
El sistema combina referencias biomédicas con reglas heurísticas para representar estados fisiológicos comparables.
11.6. Evolución estructural controlada
La modularidad permite introducir modificaciones progresivas sin alterar resultados históricos.
11.7. Lectura analítica dual: score compuesto y tendencia biométrica directa
El sistema combina scores compuestos de dominio con análisis longitudinal directo de variables diarias persistidas.
11.9. Importación automática de analítica clínica desde PDF con IA nativa
El sistema incorpora un mecanismo de ingestión de informes de laboratorio en formato PDF
que prescinde de OCR previo. El PDF se transmite directamente como documento base64
al modelo de lenguaje, que comprende la estructura del informe y extrae hasta 60 biomarcadores
mapeados al modelo de dominio AnaliticaClinica.
El diseño incorpora reglas de conversión explícitas para los casos en que distintos laboratorios emplean unidades diferentes (notación científica hematológica, PCR en mg/dL, urea/calcio/fósforo en mmol/L, T4 Libre en pmol/L), evitando errores de orden de magnitud independientemente del laboratorio emisor.
La pantalla de revisión con semáforo de rangos de referencia constituye una capa de validación interactiva que permite detectar visualmente cualquier discrepancia antes de la persistencia definitiva.
11.8. Modelo diario de balance energético y disponibilidad funcional
El sistema introduce un modelo diario específico de balance energético, basado en la integración de energía ingerida, gasto basal ajustado, gasto activo ajustado, gasto total, macronutrientes, alcohol y proteína relativa al peso corporal.
Este modelo permite distinguir entre el mero saldo calórico y la calidad funcional del día, incorporando la suficiencia proteica y la composición nutricional como elementos relevantes para la interpretación de la presión metabólica.
La existencia de una vista dinámica complementaria, basada en curva diaria por fases e índice relativo de disponibilidad energética, aporta una lectura visual y sintética del estado energético funcional, sin convertir dicho índice en magnitud clínica directa.
11.10. Informe de revisión histórica parcial con análisis IA integrado
El sistema incorpora un módulo de revisión longitudinal propio (HistoriaPacienteService)
que compila, para cualquier período seleccionado por el usuario, un informe multidimensional
que integra perfil fenotípico, evolución de los tres scores funcionales, balance energético período,
macronutrientes medios, verificación sistemática de ~55 parámetros analíticos contra rangos de referencia
clínicos y apéndice de registros diarios brutos.
El mecanismo de verificación analítica (BuildParametros) marca individualmente cada
parámetro como esencial o anormal, con resaltado visual diferenciado en el informe imprimible.
El resumen IA de cinco párrafos estructurados se genera de forma asíncrona mediante plantilla
versionada en base de datos (HistoriaPacientePromptSeeder), garantizando que la
analítica clínica figure siempre en el análisis independientemente de si los valores son normales,
y que los parámetros fuera de rango sean explícitamente contextualizados en las recomendaciones.
11.11. Sistema híbrido de estimación nutricional (OFf + IA)
El módulo de ingesta alimentaria incorpora un modo de operación híbrido que combina datos reales
de etiqueta de la API pública OpenFoodFacts (OFf) con estimación por IA como fallback.
El usuario puede alternar entre ambos modos mediante un switch en la vista de intake,
con persistencia del estado en localStorage.
En modo OFf+IA, el servicio NutritionOpenFoodFactsService busca cada alimento
en world.openfoodfacts.org con throttling de 2 peticiones concurrentes
(SemaphoreSlim) para evitar rate limiting. La selección del candidato más
relevante entre hasta 5 resultados se realiza mediante puntuación de coincidencia de palabras
(sin llamada adicional a IA). Los alimentos no encontrados y las bebidas alcohólicas van
siempre al servicio IA (INutritionAiService), que calcula el alcohol por
fórmula determinista: ml × graduación × 0,789 × 7 kcal/g.
El JSON nutricional resultante mantiene la misma estructura que el producido por el modo IA puro
(AlimentoDiaItem: name, grams, kcal, hidratos, proteinas, grasas, alcohol, sodioMg),
siendo transparente para el resto del sistema.
11.12. Modelo estadístico de impacto etílico (AlcoholCalibrationService)
El sistema incorpora un modelo propio de regresión por mínimos cuadrados ordinarios (MCO) destinado a cuantificar el efecto del alcohol sobre la variación de peso, separado del factor puro de ingesta calórica.
El modelo opera sobre el residuo diario
y_t* = ΔPeso_t + Gasto_{t-1}/7700 − F × KcalSinAlcohol_{t-1}/7700,
donde F es el factor de ingesta fijado desde UserEnergyCalibration para evitar
multicolinealidad. Estima tres coeficientes independientes:
- β_alc (inmediato): kg de variación de peso por gramo de alcohol consumido el día anterior.
- β_lag (diferido D+1): efecto residual al segundo día, asociado a supresión de GH nocturna.
- β_sleep (HRV/sueño): coeficiente del índice fisiológico compuesto (HRV, despertar nocturno, sueño profundo) del día posterior a la ingesta etílica.
A partir de los coeficientes se calcula el contrafactual: pérdida de peso estimada si el alcohol hubiera sido cero durante el período analizado. El módulo calcula también el error residual (diferencia entre pérdida calóricamente esperada y pérdida observada), que en períodos largos puede indicar compromiso de la capacidad hepática de beta-oxidación.
El resultado (CalibracionAlcoholResult) es un DTO calculado en memoria,
no persistido. La calidad del modelo se clasifica en cuatro niveles (Excelente/Buena/Aceptable/Insuficiente)
según R² y número de días con y sin consumo etílico.
11.13. Calibración diferenciada macros/alcohol y alerta de recalibración
El factor de corrección de ingesta OllamaIntakeCorrectionFactor se aplica
exclusivamente sobre el componente de macros (HC×4 + Prot×4 + Grasa×9), excluyendo el alcohol.
Las calorías del alcohol se calculan mediante la fórmula determinista (g × 7 kcal) sin aplicar
ningún factor corrector, por ser un cálculo exacto sin sesgo de estimación de IA.
Esta separación se implementa en EnergyDailyBalanceService y en
CalibrationAlertService, garantizando coherencia en todos los módulos del sistema.
El servicio CalibrationAlertService evalúa en cada primera aplicación de ingesta
del día si el balance energético acumulado de los últimos 28 días implica una variación de peso
cuya magnitud supera el umbral personalizado del usuario:
threshold = clamp(pesoActual × 0,005 ; 0,200 kg ; 0,800 kg).
Si se supera el umbral y han transcurrido ≥ 28 días desde la última calibración guardada,
el sistema genera un aviso visible en la vista de intake. El umbral y el período mínimo
son configurables en la sección CalibrationAlert del appsettings.json.
11.14. Arquitectura multiusuario: roles, contexto de sesión y mensajería asíncrona
El sistema gestiona tres perfiles mediante ASP.NET Core Identity:
Profesional (crea pacientes, gestiona su propio expediente y el de sus pacientes),
Paciente (creado por el profesional con credenciales propias, datos aislados) y
Usuario autónomo (acceso directo sin vinculación profesional).
La relación profesional-paciente se persiste en ProfesionalPacienteRelacion
con desvinculación no destructiva.
El acceso del profesional a datos del paciente se articula mediante un patrón de
contexto de sesión: IContextoUsuarioService.SetPacienteActivo()
activa el contexto de un paciente en la sesión HTTP, y
BaseContextoController.ResolveUserId() devuelve el UsuarioId
del paciente activo —previa validación de EsPacienteDelProfesionalAsync()— o
el del propio profesional si no hay contexto activo. Esto permite al profesional navegar
la plataforma completa en nombre del paciente sin modificar ningún controlador.
El módulo de mensajería asíncrona (MensajeProfesionalPaciente,
MensajesController) permite al profesional enviar
Indicaciones (unidireccionales) y SolicitudesPermiso
(el paciente puede Aceptar con o sin Rechazar con motivo registrado).
Ciclo de estado auditable: Enviado → Leído → Aceptado/Rechazado.
El proveedor de IA puede diferir por usuario (Admin = Claude API, resto = Ollama),
resuelto dinámicamente en la fábrica de IAiCompletionService.
11.15. Generación asistida por IA de documentos RGPD y contratos
El sistema incorpora un subsistema de generación automática de documentación legal orientada a la relación profesional-paciente: consentimientos informados, políticas de privacidad y contratos de servicio, adaptados al perfil del profesional y conformes con el Reglamento General de Protección de Datos (RGPD) y la normativa española.
Los servicios RgpdDocBuilderService, RgpdDocumentService,
RgpdExportService y RgpdDocSeeder articulan la construcción,
persistencia y exportación de los documentos. Las plantillas son versionadas y
configurables mediante el mismo sistema de prompts declarativos que el resto de módulos IA.
11.16. Derecho al olvido (Art. 17 RGPD): flujo de baja y copias de seguridad independientes
El BajaUsuarioOrchestrator implementa el flujo de baja de cuenta como una
máquina de estados (SolicitudBajaUsuario:
Solicitada → Verificada → [ProfesionalNotificado] → BackupPendiente → BackupGenerado →
Ejecutada → Completada, o Cancelada). Si el paciente tiene un profesional
vinculado activo, este es notificado por email y se abre un periodo de gracia de
7 días naturales antes de poder generar el backup y ejecutar el borrado. Las
cuentas con rol Administrador no pueden solicitar ni ejecutar su propia baja (comprobación
explícita de rol en SolicitarBajaAsync y EjecutarBorradoAsync).
El borrado nunca se ejecuta sin backup previo: GenerarBackupAsync
construye, vía IUserBackupService.GenerateBackupZipAsync, un ZIP autocontenido
con todos los datos del usuario en JSON y un visor HTML standalone
(BackupViewerHtmlBuilder). El administrador debe confirmar la custodia del
backup (ConfirmarCustodiaBackupAsync) antes de que EjecutarBorradoAsync
quede habilitado, y UserDeleteService ejecuta entonces el borrado en cascada de
todos los datos del usuario (perfil, BioData, analíticas, energía, mensajería, documentos RGPD...).
Copia de seguridad independiente del borrado: dado que IUserBackupService
no depende de ninguna SolicitudBajaUsuario, el panel de administración
(AdminController.DescargarCopiaSeguridad) expone esta misma generación de
backup como una acción autónoma sobre cualquier usuario, sin crear ni requerir ninguna
solicitud de baja — es decir, el administrador puede obtener en cualquier momento una
copia de seguridad completa de los datos de un usuario sin que ello implique ni inicie
ningún proceso de eliminación de cuenta.
Restauración de datos de uso desde una copia de seguridad:
IUserBackupRestoreService.RestaurarDatosUsoAsync (acción
AdminController.RestaurarDatosUso) permite, a partir del mismo ZIP de backup,
reinsertar en una cuenta activa únicamente los datos de uso diario:
BioDataDiaria y AnaliticaClinica. Por cada registro del backup
se comprueba si ya existe un registro para esa fecha (Fecha /
FechaAnalisis) en la cuenta destino; si existe, se omite — los datos ya
presentes en BD son siempre prioritarios sobre la copia de seguridad, que por construcción
nunca puede ser más reciente. Solo se insertan las fechas que faltan, reasignando
Id=0 (autogenerado) y el UsuarioId destino. La acción devuelve un
resumen (RestoreDatosUsoResult) con el número de registros insertados y
omitidos por cada tabla.
Esta restauración se limita deliberadamente a los datos crudos de uso: no toca
PerfilPersonal, mensajería ni documentos RGPD, y tampoco reinserta las
tablas de históricos derivados (HealthScoreHistory,
HealthEvolutionSnapshot, RecoveryBaseline/RecoveryDailyScore,
EnergyDailyBalance) — una vez restaurados los datos crudos, estos históricos
se regeneran con los servicios de recálculo ya existentes
(IEnergyDailyBalanceService.RecalculateAllAsync,
IRecoveryService.CalcularHistoricoAsync / RecalcularBaselineAsync,
IHealthScoreBackfillService.BackfillAsync). La recreación completa de una
cuenta eliminada (perfil, relaciones, mensajería, documentos RGPD, conexión Oura...) queda
deliberadamente fuera de la aplicación, como proceso manual extraordinario de back-office.
11.17. Módulo de detección y cuantificación de adaptación metabólica
El sistema incorpora un módulo propio (MetabolicAdaptationService) que cuantifica la
adaptive thermogenesis mediante la comparación entre el TDEE teórico por el modelo energético
(EnergyDailyBalance.EnergiaGastoTotalKcal) y el TDEE real estimado por balance de masa
(TDEE_real = (ΣIngesta_corr − ΔPeso_kg × 7 700) / n).
El módulo reutiliza el factor de corrección de ingesta existente (OllamaIntakeCorrectionFactor)
sobre macros y aplica regresión OLS sobre la serie de peso para aislar la variación de masa real del ruido
hídrico diario. La adaptación se clasifica en cuatro niveles y los snapshots se persisten en
MetabolicAdaptationSnapshots (entidad propia, con FK a AspNetUsers).
El módulo genera una serie histórica de 12 ventanas de 28 días y emite alertas automáticas de reactivación metabólica (adaptación > 250 kcal, período ≥ 20 días) y de cobertura proteica insuficiente (< 80 %). La vista incluye un modal de información científico exhaustivo con bibliografía (Hall 2016, Rosenbaum, MATADOR/Byrne 2017), sin dependencia de nuevos servicios IA.
12. Estado de protección y derechos de autor
Estado registral: Obra software en trámite de inscripción en el Registro de la Propiedad Intelectual.
Derechos de autor:
© 2026 Ricardo M. Trigo Calonge.
Todos los derechos reservados.
Queda prohibida la reproducción, distribución, comunicación pública o transformación, total o parcial, del código fuente, modelos estructurales, arquitectura software, algoritmos, lógica funcional y documentación técnica asociada, sin autorización expresa del titular.
13. Bibliografía científico-técnica de referencia
La siguiente bibliografía se incorpora como fundamento general de los criterios biomédicos y de las heurísticas funcionales empleadas por el motor de scoring.
- American Diabetes Association Professional Practice Committee. Diagnosis and Classification of Diabetes: Standards of Care in Diabetes—2026. Diabetes Care. 2026;49(Suppl. 1):S27-S49.
- Watson NF, Badr MS, Belenky G, et al. Recommended Amount of Sleep for a Healthy Adult. Journal of Clinical Sleep Medicine. 2015;11(6):591-592.
- Arantes FS, Oliveira VR, Leão AKM, et al. Heart rate variability: A biomarker of frailty in older adults? Frontiers in Medicine. 2022;9:1008970.
- World Health Organization. WHO guideline on use of ferritin concentrations to assess iron status in individuals and populations. Geneva: WHO; 2020.
- McEvoy JW, McCarthy CP, Bruno RM, et al. 2024 ESC Guidelines for the management of elevated blood pressure and hypertension. European Heart Journal. 2024.
- Zhang D, Shen X, Qi X. Resting heart rate and all-cause and cardiovascular mortality in the general population: a meta-analysis. CMAJ. 2016;188(3):E53-E63.
- Rosanoff A, Dai Q, Shapses SA. Recommendation on an updated standardization of serum magnesium reference ranges. Magnesium Research. 2022;35(3):114-117.
- Bull FC, Al-Ansari SS, Biddle S, et al. World Health Organization 2020 guidelines on physical activity and sedentary behaviour. British Journal of Sports Medicine. 2020;54(24):1451-1462.
- Grundy SM, Stone NJ, Bailey AL, et al. 2018 AHA/ACC Guideline on the Management of Blood Cholesterol. Circulation. 2019;139(25):e1082-e1143.
- Booth FW, Roberts CK, Laye MJ. Lack of Exercise Is a Major Cause of Chronic Diseases. Comprehensive Physiology. 2012;2(2):1143-1211.
- Fried LP, Tangen CM, Walston J, et al. Frailty in older adults: Evidence for a phenotype. Journals of Gerontology Series A. 2001;56(3):M146-M156.
- Visser M, Schaap LA. Consequences of sarcopenia. Clinical Geriatric Medicine. 2011;27(3):387-399.
- Hall KD, Kahan S. Maintenance of Lost Weight and Long-Term Management of Obesity. Medical Clinics of North America. 2018;102(1):183-197. [Biggest Loser study follow-up; adaptive thermogenesis]
- Byrne NM, Sainsbury A, King NA, Hills AP, Wood RE. Intermittent energy restriction improves weight loss efficiency in obese men: the MATADOR study. International Journal of Obesity. 2018;42(2):129-138.
- Rosenbaum M, Leibel RL. Adaptive thermogenesis in humans. International Journal of Obesity. 2010;34(Suppl 1):S47-S55.
- Trexler ET, Smith-Ryan AE, Norton LE. Metabolic adaptation to weight loss: implications for the athlete. Journal of the International Society of Sports Nutrition. 2014;11(1):7.